Contents (A) State-Contingent Markets The "state-preference" approach to uncertainty was introduced by Kenneth J. Arrow (1953) and further detailed by Gérard Debreu (1959: Ch.7). It was made famous in the late 1960s, with the work of Jack Hirshleifer (1965, 1966) in the theory of investment and was advanced even further in the 1970s with developments of Roy Radner (1968, 1972) and others in finance and general equilibrium. The basic principle is that it can reduce choices under uncertainty to a conventional choice problem by changing the commodity structure appropriately. The state-preference approach is thus distinct from the conventional "microeconomic" treatment of choice under uncertainty, such as that of von Neumann and Morgenstern (1944), in that preferences are not formed over "lotteries" directly but, instead, preferences are formed over state-contingent commodity bundles. In its reliance on states and choices of actions which are effectively functions from states to outcomes, it is much closer in spirit to Leonard Savage (1954). It differs from Savage in not relying on the assignment of subjective probabilities, although such a derivation can, if desired, be occasionally made. The basic proposition of the state-preference approach to uncertainty is that commodities can be differentiated not only by their physical properties and location in space and time but also by their location in "state". By this we mean that "ice cream when it is raining" is a different commodity than "ice cream when it is sunny" and thus are treated differently by agents and can command different prices. Thus, letting S be the set of mutually-exclusive"states of nature" (e.g. S = {rainy, sunny}), then we can index every commodity by the state of nature in which it is received and thus construct a set of "state-contingent" markets. Let us denote the set of mutually-exclusive states as S, abusing notation, let us assume that the number of states is also S (i.e. #S = S). If we have n physically-different commodities and S states of the world, we really have, in fact, nS commodities and thus nS prices. Thus the commodity space X is a subset of RnS. Letting xis be the amount commodity i delivered in state s, then we can conceive of the set of commodities in the n ´ S array shown in Table 1. Letting pis be the price of commodity i in state s, then there is a similar array of prices.
Notice that a single row of the state-contingent array in Table 1 is the commodity bundle delivered in a particular state of the world. Thus, for any state s Î S, we can define xs = [x1s, x2s, ..., xns] as a state-contingent bundle (bundle of commodities received in state s) and define ps = [p1s, p2s, ..., pns] as the state-contingent price vector (price of commodities in state s). Notice that we do not rely on univariate outcomes, i.e. we do not restrict ourselves to "money" returns but rather allow entire commodity bundles as outcomes in any state. Alternatively, a single column of the array in Table 1 denotes the different amounts of a particular commodity that will be obtained in different states of the world. Thus, defining xi = [xi1, xi2, .., xiS]¢ as the ith column of this array, then we can view xi as a random variable mapping from states of the world to particular amounts of commodity i, i.e. xi: S ® R. Similarly, a set of state-contingent prices pi = [pi1, pi2, .., piS], denotes the different prices commodity i can take in different states of the world, thus pi can be viewed also as a random variable mapping states of the world into prices of commodity i, pi: S ® R. A specific commodity bundle, x, is a set of state-contingent vectors, x = [x1, .., xS], thus a single commodity bundle collapses this entire array into a single vector:
and a single set of prices, p, is a set of state-contingent price vectors, p = [p1, .., pS], or:
Consequently, a particular bundle x bought by a consumer could include things such as "raincoat when raining", "ice cream when sunny", "hat when raining", "hat when sunny", etc. and the cost of this bundle, px, would be the quantity of each state-contingent good bought multiplied by its state-contingent price. In the state-preference approach, agents maximize utility functions defined over bundles of state-contingent commodities. With n physically-differentiated commodities and S states, so that commodity space is X Í RnS, then preferences are defined over bundles of state-contingent commodities, i.e. ³ h Í X´ X. If preferences have the regular Arrow-Debreu properties over X, then we can define a quasi-concave utility function U: X ® R representing preferences. Notice that these are not preferences over "lotteries" as in von Neumann-Morgenstern; with the construction of state-contingent preferences, the notion of randomness is almost swept under the rug. Note, furthermore, that U is quasi-concave, thus the Arrow-Pratt notions of risk-aversion do not necessarily translate easily into this context. Nonetheless, we can connect the state-preference theory with Savage's (1954) subjective expected utility and the theories of risk-aversion, by assuming that there exists a state-independent utility function u: C ® R, i.e. a real-valued mapping from the physically-differentiated commodity space C Í Rn. In this case, preferences over state-contingent commodities can be summarized by an expected utility function of the following form:
so the utility of a commodity bundle x is the sum of elementary (state-independent) utilities obtained from state-contingent bundles, u(xs), weighted by the subjective probabilities, p 1, .., p S. As in Savage, a particular p s is the agent's subjective assessment of the likelihood of a particular state s Î S emerging. Thus, a vector of subjective probabilities, p = [p 1,... p S] where å sÎ S p s = 1, represents an agent's beliefs about the likelihood of the occurrence of difference sates. Similarly, we can connect this with risk-aversion by arguing that the relative quasi-concavity of the utility function U in state contingent commodities represents the degree of risk-aversion. However, although we can sometimes argue that the particular form of the utility function U:X ® R captures people's beliefs about states and their attitudes towards risk, this is not a necessary part of the state-preference construction and indeed the entire analysis could proceed without it. It is not necessary that preferences in this scenario be reconciled with Savage's (1954) axioms nor is it always desirable that they are so. For instance, we may want utility to be state-dependent as a way of capturing, say, the notion of "random preferences". In this case, even if we could extract subjective probabilities p 1, .., p S, we would only achieve in this case a decomposition along the lines of U(x) = å sÎ S p sus(xs) where the important subscript s on the elementary utility function indicates that utilities are themselves state dependent. In this case, the same good in a particular state is simply valued more by the consumer than the same good in another state independently of the probabilities of the states occurring. Nonetheless, let us proceed as if U: X ® R does have an expected utility construction with state-independent utility. In this case, the individual optimum is defined by the following optimization problem:
where es = [e1s, e2s, .., ens] is the agent's endowment vector if state s occurs. Setting up the Lagrangian:
where l is the Lagrangian multiplier, we obtain the set of first order conditions by differentiating this with respect to every state-contingent commodity xis:
(we are assuming an interior solution). Of course, the budget constraint is fulfilled then, so å sÎ S pses = å sÎ S psxs. Notice that as there is a single multiplier, l , across the first order conditions, then this implies that at the individual optimum, for any particular physically-defined commodity i:
i.e. the expected marginal utility of commodity i per unit of money income will be equated across states. Following Arrow (1953), this condition has become known as the "fundamental theorem of risk-bearing". Notice that if we did not assume the expected utility decomposition, then the numerator of each equation would be simply denoted ¶ U/¶ xis, the partial derivative of the original utility function with respect to state-contingent commodity xis or, if we could extract subjective probabilities, we would nonetheless retain the state-dependent utility functions and so have p1u1¢(xi1)/pi1 = p 2u2¢(xi2)/pi2, etc. as our fundamental theorem. We can illustrate the individual optimum via Figure 1 where we have a single commodity (call it "money" or "consumption") and two states, S = (1, 2). Thus, a commodity bundle, in this case, is a pair of state-contingent commodities, x = (x1, x2) where x1 is the amount of the commodity delivered in state 1 and x2 the amount of the same commodity delivered in state 2. Obviously, as n = 1 and S = 2, then the commodity space X Í R2, and is shown in Figure 1. We shall assume that there exists a utility function U: X ® R that represents preferences over X and we shall assume that U takes on the expected utility decomposition, so U(x) = p1u(x1) + p2u(x2), where p 1, p 2 are the subjective probabilities of state 1 and 2 happening (thus p 1 + p 2 = 1). As U is quasi-concave over X, then the upper contour set is a series of convex indifference curves as depicted in Figure 1. The slope of the indifference curves, therefore, are easily determined by totally differentiation:
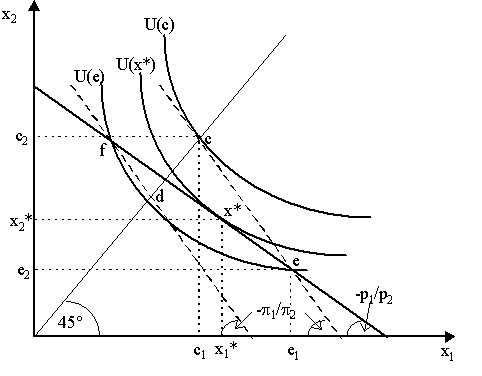
where the right-hand side is the (negative of) the marginal rate of substitution between consumption in the two states. Thus, note that when x1 = x2 (as at point c in Figure 1), then u¢ (x1) = u¢ (x2), so the slope of the indifference curve is reduced to -(p 1/p 2). So, along the 45° line (the "certainty line"), the slope of every indifference curve will be equal to -(p 1/p 2). Unless the agent assigns equal subjective probability assessments to both states, p 1/p 2will generally not be equal to 1. Once again, we would like to remind ourselves that these last points are only true if we assume that agents have underlying state-independent utility function. If utility were state-dependent so that the slope of the indifference curve is dx2/dx1|u = - p 1u1¢ (x1)/p 2u2¢ (x2) then the reason that the slope of the indifference curve on the 45° might be different from 1 could still be due to different beliefs about the probability of states occurring. However, it may also be that agents have different assessments about the utility value of the same consumption in different states. It may simply be, for instance, that "consumption when raining" is simply more valuable to the consumer than "consumption when sunny". Thus, ostensibly, both beliefs and state-dependent preferences can explain why the slope of the indifference curve is not equal to 1 on the 45° line. However, by assuming that preferences are state-independent, as we did in order to obtain our expected utility decomposition, then the only explanation that remains is differing beliefs.
As we noted earlier, the individual is endowed with a bundle of state-contingent commodities, in this case e = (e1, e2), depicted in Figure 1 as point e. As we can see, e1 > e2, so the agent's endowment yields more of the good in state 1 than in state 2. If the agent consumes his own endowment, he attains utility level U(e). However, we shall assume the existence of state-contingent markets where the agent can trade state-contingent commodities. Let p1 be the price of the good in state 1 and p2 the price of the good in state 2 (which we shall assume is known and given). These will thus define a budget constraint passing through e, as shown by the line in Figure 1 with slope -p1/p2. Consequently, the agent faces the following optimization problem:
Setting up a Lagrangian, and deriving the first order conditions for an interior solution, we obtain:
where l is the Lagrangian multiplier. Thus, combining the first two, we can notice that:
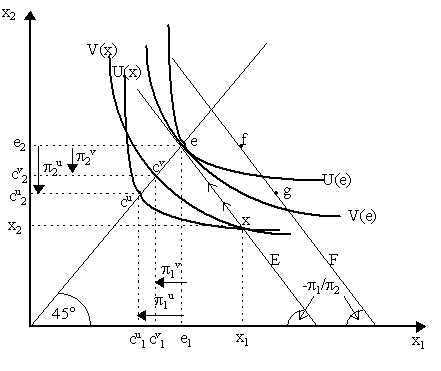
thus the agent will choose his optimal bundle of state-contingent commodities where the highest indifference curve is tangent to the budget constraint. The bundle x* = (x1*, x2*) yielding utility U(x*) in Figure 1 is thus the individual optimum for this simple two-state case. There are a few things worth noticing. The first is that once again, the fundamental theorem of risk-bearing holds here as the first order conditions imply that p 1u¢ (x1)/p1 = p 2u¢ (x2)/p2 so that expected marginal utility per dollar is the same across states. The second thing is that x* is not on the certainty line - x1* > x2*, thus the agent will receive different amounts in different states. Now, the consumer could have purchased a bundle which had no risk, such as allocation d on the certainty line, but notice that an indifference curve that would pass through d would yield a utility that would be lower than u(x*). Why did this happen? The answer can actually be deduced from Figure 1: namely, the relative prices of the state-contingent commodities do not correspond to the agent's subjective assessment of the likelihood of both states. Specifically, notice that p 1/p 2 > p1/p2. This implies that market prices are not "actuarially fair". For instance, suppose that probability assessments are p 1 = 0.75 and p 2 = 0.25 while the market prices p1 = 0.5 and p2 = 0.5, thus p 1/p 2 = 3 > 1 = p1/p2. Thus, the agent believes the probability of state 1 is much greater than that of state 2, yet the market prices goods in both states the same. Because the agent is endowed mostly with state 1 good, he will get a lower price for selling it than if the market shared his probability assessments. Consequently, he will not sell most of his good 1 and will move to a position, x*, where he still has a random outcome. If prices were "actuarially fair", i.e. if they coincided with the agent's probability beliefs so that the budget constraint had slope -p 1/p 2, then notice that the budget constraint would effectively be the dashed line passing through endowment e in Figure 1. In this case, the consumer optimum would be, as we see, c = (c1, c2) and thus he would move onto the 45° certainty line and achieve a much higher level of utility U(c) than he had before. However, this does not mean that an agent would always prefer actuarially fair prices. There are gainers and losers in most market situations. For instance, suppose that the agent had endowment at point f in Figure 1. In this case, facing unfair prices (p1, p2) but keeping the same beliefs (p 1, p 2) notice that the agent would move again to the optimum x* = (x1*, x2*). This time, he has a lot of state 2 good to sell and the market values state 2 good more than he thinks it likely that state 2 happens - thus, this agent is getting a deal at the unfair prices. However, if prices were "fair" in this situation, then the budget constraint would be a line passing through f with slope -p 1/p 2 in Figure 1. It is easy to visualize that in this case, the agent would move to the certainty allocation at point d and thus we can see that the utility achieved by the agent in this case will be lower than U(x*). Thus, an agent with endowment at f would lose out if the market prices were made actuarially fair; he would prefer that they were kept at their "unfair" rate of -(p1/p2). A few more things can be deduced from this simple diagram. Firstly, if an agent starts from a position of certainty (i.e. on the 45° line) and is offered actuarially fair prices, he will not move to a position off the 45° line. This is easily visualized if we consider the agent starting at allocation c and prices being fair at -p 1/p 2 so that the dashed line is the budget constraint. In this case, U(c) is the highest utility he can attain. Intuitively, this implies that starting from a position of certainty, an agent will not take "fair bets". He will, however, take unfair bets if the odds are to his advantage (as in the case of an agent starting at d in Figure 1 and then being offered unfair prices which took him through to, say, x*). The second result is that if an agent starts in an uncertain situation (such as e or f), then he will move to a certainty position if the price is fair. However, note that from a "financial" perspective, as we shall discuss later, he is actually purchasing a risky asset to undertake this move! However, the purchase of the risky asset is in order to offset the riskiness of his original endowment and thus, yield certainty in the end. However, he will not necessarily move to certainty position if the odds are unfair but might optimally take a risky situation, usually where the odds are favorable (e.g. move from e or f to x*). (C) Yaari Characterization of Risk-Aversion We have already noted how the shape of the indifference curves can reflect the subjective assessments of the probabilities of different states. Let us now turn to the issue of how they can reflect "risk-aversion". In the theory of Arrow (1965) and Pratt (1964), risk-aversion is characterized by the concavity of the utility function over money income. As the indifference curves in our simple two-state case are merely the upper contour set of a quasi-concave utility function over a single commodity with two payoffs, then risk-aversion is not clear. However, if we imposed concavity of utility, and thus risk-aversion, this would also translate into convex indifference curves in our simple diagram in the space of state-contingent commodities. The theory of risk aversion with the state-preference approach was first laid out by Menachem Yaari (1969). To see this, examine Figure 2 where we have two agents, U and V, with two types of indifference maps. Obviously, the indifference curves U are more "convex" than the indifference curves V. Does this imply that U is more risk averse than V? There are two ways we are going to answer this. The first appeals to the risk-premium story similar to Arrow-Pratt, whereas the second involves a new definition of risk-aversion. Let us begin by examining Figure 2. Let E = p 1x1 + p 2x2 denote a particular level of (subjectively) expected return, thus the line E with slope -p 1/p 2 represents all the combinations of good in state 1 and good in state 2 that yields the same expected return E. Similarly, let F = p 1x1¢ + p 2x2¢ be another level of expected return, thus the line F which also has slope -p 1/p 2 represents all the combinations of goods in both states that yield the same expected return F. As the line E lies everywhere below F, then every allocation on E has a lower expected return than any allocation on F. Consider now the initial risky allocation x = (x1, x2) in Figure 2. At this allocation, we have utility levels U(x) and V(x) for the two agents. Now, we want to obtain risk premia, thus we must look for certainty-equivalent allocations. These are easily traced by moving along the indifference curves to the 45° certainty line. Obviously, allocation cu = (cu1, cu2) on the 45° line yields the same utility, U(x), as did allocation x, thus, cu represents agent U's "certainty-equivalent" allocation. Similarly, cv = (c1v, c2v) yields the same utility to the second agent, V(x), that was obtained at x, thus cv is agent V's "certainty-equivalent" allocation. In order to calculate the risk premia, we have to deduce how much of each commodity each agent would be willing to give up to move from allocation x to their certainty-equivalent allocations cu and cv. Obviously, in both cases, they both give up a lot of good 1, but they would demand a little bit of good 2 in compensation, thus it might be hard to tell. However, we know that as allocation e and allocation x lie on the same curve E, then they share the same expected return. Thus, one avenue would be to move along the E line from x to e and then compute the risk-premium as what it will take to move from e to cu and cv respectively. Thus, the "risk-premium" that agent U would pay would be now a "bundle" p u = (p 1u, p 2u) = (e1 - cu1, e2 - cu2) and, similarly, the risk premium agent V would pay would be bundle p v = (p 1u, p 2u) = (e1 - cv1, e2 - cv2). We can now posit the story analogously to Arrow-Pratt: if any of the components in the risk-premia p u or p v are positive (or at least none is negative), then the agent is risk-averse. We can see that clearly that both agents U and V are risk-averse as both p u and p v are positive in their components. Analogously, if there was a risk-neutral agent, then his risk-premium would be zero in both components. Notice that in this case, he would have to have a linear indifference curve that passed through both points e and x, thus e would be his certainty-equivalent allocation. Conversely, if there were a risk-loving agent, then he would have non-convex indifference curves (or rather, concave to the origin) so that he would actually pay to move from x (or rather e) to his certainty-equivalent point - thus the components of his risk-premium bundle would be negative. As we see, we can obtain a characterization of risk-aversion, neutrality and proclivity by a "risk-premium" argument analogous to Arrow-Pratt. What is more, we can use it as a measure. It is obvious from Figure 1 that as cv lies to the northeast of cu that consequently p v < p u, i.e. the more risk-averse agent U pays a higher premium (in both components) than V. Thus, we would say that U is more risk-averse than V.
There are some fudgy sides to the risk-premium story outlined above, thus we would like to quickly turn to Menachem Yaari's (1969) criteria for risk-aversion. Specifically, suppose we begin with allocation e which yields expected return E in Figure 1. Obviously, the agents now have U(e) and V(e). We consequently define risk aversion as follows:
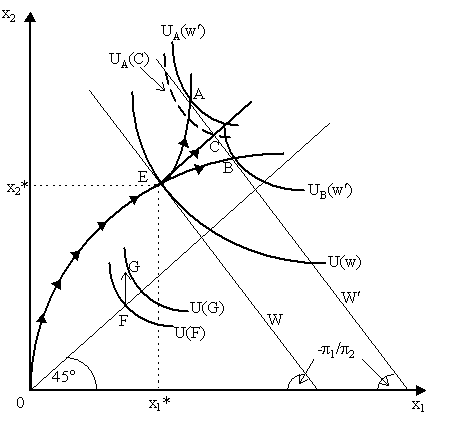
What this means can be gathered immediately from Figure 1 by examining points f and g on the F line. Obviously, as E < F, then f and g yield a higher expected return than e. It is noticeable that both agents U and V would reach a higher indifference curve - and thus a higher expected utility - if they were given f. Thus, both agents V and U would accept the risky allocation f instead of e. But the interesting point is g. Obviously, agent V would also obtain a higher level of utility at g than he would at e, thus he would accept allocation g. However, it is noticeable that agent U would have a lower expected utility at g than he would at e, thus U would not find risky allocation g acceptable. Thus, starting from e, there is at least one risky allocation that V would accept but U would not. We can immediately see from the diagram that, consequently, the set of risky allocations that U would accept is a strict subset of the set of risky allocations acceptable to V - thus, by the Yaari definition of risk-aversion, U is more risk-averse than V. In sum, we can attempt to link the three ideas together: namely, that U is more risk-averse than V if (i) the indifference curves of U are "more convex" than V; (ii) that the risk-premium bundle paid by U is greater than that paid by V; (iii) that V will accept risky allocations that U will not accept. However, we caution that we are being a bit fudgy here: the assumption of the existence of state-independent utility function is crucial. Let us now turn to Yaari's (1969) more interesting constructions on characterising increasing/constant/decreasing risk aversion. Specifically, we wish to characterize risk-aversion in its appeal to changes in wealth. We wish to trace out, therefore, a wealth-expansion path as shown in Figure 3 by the OE curve (ignore U(F) and U(G) in Figure 3 for now). Now, recall that wealth is endowment, thus assuming prices are actuarially fair (i.e. market prices and subjective beliefs coincide), then at any particular level of endowment e = (e1, e2), we can define total wealth as W = p 1e1 + p 2e2 which serves as our budget constraint. This is shown in Figure 3 by line W with slope -p 1/p 2. If endowment increases to e¢ = (e1¢ , e2¢ ) and prices remain the same, then wealth increases to W¢ = p 1e1¢ + p 2e2¢ and so we obtain a correspondingly higher budget line W¢ also with slope -p 1/p 2. At any budget constraint, we can define the consumer optimum at the tangency of the highest indifference curve and the budget constraint. Thus, in Figure 3, when wealth is W, then E = (x1*, x2*) represents the optimum achieving the denoted utility level U(w).
The line OE denotes the wealth expansion path which is constructed by tracing the individual optimums at different levels of wealth. Thus, at W, we have point E lying on the expansion path. What we wish to deduce from this, as in the Arrow-Pratt case, is the concept of decreasing/increasing rates of risk-aversion with respect to wealth. The shape of the wealth expansion path in Figure 3 is arbitrarily drawn up to point E. However, it is what happens after that which matters for our analysis. There are many paths which the wealth expansion path can take after E: for instance, we can go towards A or towards B or even towards C. In Figure 3 we have drawn two specific individual optima at W¢ - namely, points A and B, which yield solid line indifference curves UA(w¢ ) and UB(w¢ ) respectively. It is important to note that the middle path EC is parallel to the 45° line, thus implying that the path EA is moving away from the 45° certainty line (towards greater risks) and the path EB is moving towards the 45° certainty line (thus towards greater certainty). Thus, we would like to say that if the wealth expansion path follows the EA track, then we have decreasing absolute risk-aversion whereas if it follows the EB track then we have increasing absolute risk-aversion and, finally, if it follows the EC track, then we have constant absolute risk aversion. How can we deduce this? Algebraically, it is not very difficult. As W is parallel to W¢ , then the slopes of the indifference curves at the optimum when wealth is W¢ is the same as at E. Thus, if A is the new optimum at W¢ , then the slope of UA(w¢ ) at A is the same as U(w) at E. If, in contrast, B is the new optimum at W¢ , then the slope of UB(w¢ ) at B is the same as U(w) at E. Now, recall that the marginal rate of substitution (the negative of the slope of the indifference curve) at point E is p 1u¢ (x1*)/p 2u¢ (x2*). Differentiating with respect to the logs of this term we obtain:
Now, as the EC line is parallel to the 45° line, then dx1 = dx2 as we move along EC. This implies that along EC:
Now suppose there is an increase in wealth and we move along EA to point A. We can see in Figure 3 that if UA(w¢ ) is the optimum indifference curve, then the lower, dashed-line indifference curve UA(C) represents the indifference curve at C if EA is the true expansion path. As the MRS at A is the same as the MRS at E, then what is the implied MRS at C? Obviously it must be less because of declining marginal rates of substitution, i.e.
thus marginal rate of substitution must have declined in moving from E to C. Thus, the implication is that:
As we are above the 45° line, we know x2* > x1*. Thus, if consumption in state 2 good is greater than consumption in state 1 good, then the Arrow-Pratt measure of absolute risk aversion of state 2 good is smaller than the absolute risk-aversion in state 2. But recall that state 2 good is the same "money" good as state 1 good, thus x2* > x1* implies that in "moving" from x1 to x2 we are "increasing wealth". Thus, the result that -u¢ ¢ (x1*)/u¢ (x1*) > -u¢ ¢ (x2*)/u¢ (x2*) implies that as "wealth" increases, the rate of absolute risk-aversion falls. Thus, the wealth-expansion path EA implies that we have decreasing absolute risk aversion (DARA) in the sense of Arrow-Pratt. What if EB was the true wealth-expansion path and not EA? The analysis would be effectively the same. We would notice that the MRS of UB(w¢ ) at B is the same as U(w) at E, thus we would find that the corresponding MRS at C would be greater than the MRS at B, thus:
which implies, of course, that:
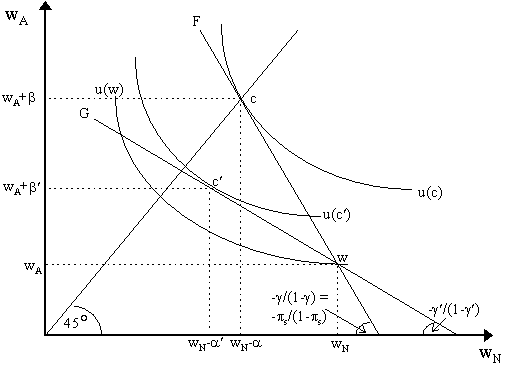
But as we still have it that x2* > x1* above the 45° line, then this states that a rise in income leads to a rise in risk-aversion. Thus, the path EB represents increasing absolute risk-aversion (IARA). It is easy to notice that if EC was the true path, then -u¢ ¢ (x1*)/u¢ (x1*) = -u¢ ¢ (x2*)/u¢ (x2*), so that we would have constant absolute risk-aversion (CARA). Finally, if the wealth-expansion path was below the 45° line, then we would reverse our inequalities for x1* and x2* and try to tell the story that way. Of course, all this is intuitive given Figure 1: as EA is moving towards riskier and riskier allocations, then as wealth increases, his tolerance for risks is rising - thus his absolute risk aversion declines. Similarly, as OB is moving towards more certain allocations, so he must have increasing absolute risk-aversion. How can we connect this conception of risk-aversion with the older one of "more convex" indifference curves? This is easy to tell heuristically by using our previous formula. Suppose we are at a point on the certainty line, such at point F in Figure 3, thus with utility U(F). So MRSF = p 1u¢ (x1*)/p 2u¢ (x2*) = p 1/p 2. Keeping x1 constant, let x2 rise, so dx2 > 0 and dx1 = 0 - thus we have a vertical shift from F to G in Figure 3. Now, convexity of indifference curve implies that the MRS must rise so the MRSG must be greater than MRSF. Thus, by our previous formula: dln(MRS) = - [u¢ ¢ (x2*)/u¢ (x2*)]·dx2 > 0 so the rise in dx2 leads to an increase in MRS. As dx2 > 0, then for this to hold true it must be that - u¢ ¢ (x2*)/u¢ (x2*) > 0, i.e. we have positive risk-aversion. If MRS did not change with the increase in x2 (i.e. if indifference curves were linear) then: dln(MRS) = - [u¢ ¢ (x2*)/u¢ (x2*)]·dx2 = 0 so, as dx2 > 0, then - u¢ ¢ (x2*)/u¢ (x2*) = 0, i.e. risk-neutrality. Finally note that if there is an agent v whose MRS rises even more from the same change in dx2, then we can see that [v¢ ¢ (x2*)/v¢ (x2*)]·dx2 > [u¢ ¢ (x2*)/u¢ (x2*)]·dx2 > 0, i.e. agent v has a greater degree of risk-aversion. Thus, the characterization of risk-aversion by the "convexiness" of the indifference curves was not wholly a wild conjecture. Insurance is a natural application of the state-preference approach precisely because it is a quite explicit "state-contingent" contract: i.e. it pays an indemnity if, say, a particular accident happens. We could, however, formulate the same problem with conventional expected utility, and the analogue is quite straightforward. The state-preference approach to the problem of optimal insurance was initiated by Kenneth J. Arrow (1963, 1965), Robert Eisner and R.H. Strotz (1963), Borch (1968) and many others. The extension of this analysis to account for asymmetric information problems shall be considered elsewhere. The simplest model is a two-state model with a fixed premium per dollar of coverage, g . The set of states is S ={A, N}, where A is a state where an accident happens, and in N, no accident happens. Let endowed income be w = {wA, wN}, thus wA is wealth if an accident happens and wN is wealth if no accident happens. Obviously, wA < wN, so the "loss" incurred in an accident will be wN - wA > 0. As a consequence, as shown in Figure 4, state-dependent endowment w lies below the 45° certainty line. We assume the existence of a state-independent utility function defined over payoffs, thus:
represents the expected utility of the agent at the endowment point. This is shown in Figure 4 as U(w). Note that p s is the subjective probability that an accident will happen (and thus (1-p s) is the probability that it will not). An insurance contract can be described as c = (b , a ) where a is the premium payment if there is no accident and b is the net indemnity if there is an accident. Thus, if an agent purchases the insurance contract c = (b , a ), then expected utility becomes:
However, a and b are not constants but rather variables depending on C, the total amount of coverage chosen by the agent. We can let the total premium paid be proportional to the coverage, thus a = g C where g Î [0, 1] is the premium per dollar of coverage. Net indemnity is b = C - g C, i.e. the amount of coverage minus a premium payment. It is easy to notice that the expected profits of the insurance company (assuming there is only one agent, or type of agent) are (1-p s)a - p sb . If profits are zero, then (1-p s)a - p sb = 0 which yields, upon rearranging, p s/(1-p s) = a /b so the ratio of premium payment to net indemnity is equal to the subjective odds of an accident. Replacing b = (1-g )C and a = g C, then this implies that p s/(1-p s) = g /(1-g ), which implies, thus, that p s = g , or the premium per dollar of coverage is equal to the subjective probability of an accident. This is a "fair" insurance contract. Consequently, the "fair insurance" line passing through w in Figure 4 (denoted F) would represent the series of contracts where g /(1-g ) = p s/(1-p s) for different degrees of coverage, and it is this that will act as the agent's budget constraint. The agent's objective is to find the optimal amount of insurance coverage C given some premium per dollar of coverage, g . Thus the optimization problem is:
which yields the first order condition:
or, rearranging:
Now, if insurance is "fair", i.e. if g = p s, then this reduces to:
so the marginal utility of a bad state is equal to that of a good state. This implies that (with state-independent utility), wA + C - g C = wN - g C, which implies, in turn, that C = wN - wA, i.e. the agent takes full coverage so that the entire income loss from an accident is recovered. The optimal coverage is shown in Figure 4 by the allocation c = (wN-a , wA + b ) where the highest indifference curve U(c) is tangent to the fair insurance line F on the 45° certainty line.
The full coverage result depends crucially on the assumption of "fair insurance", or g = p s. Suppose, however, that the firm decides to make extraordinary profits, so (1-p s)a - p sb > 0. This implies that g /(1-g ) > p s/(1-p s) or, simply, g > p s, so that the premium per unit of coverage exceeds the probability of an accident. In the agent's perspective, these is "unfair" insurance and it is captured by the unfair insurance line G in Figure 4 with slope g ¢ /(1-g ¢ ). In this case, the consumer's first order condition implies that:
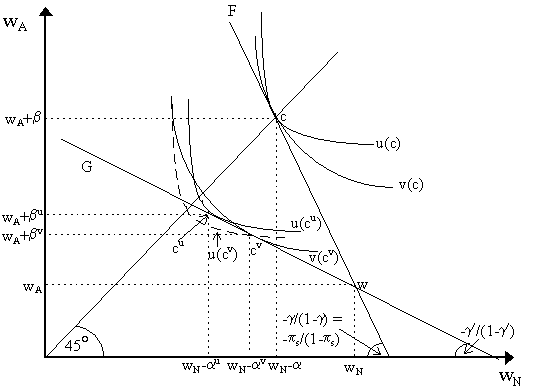
so the marginal utility of a good state is less than the marginal utility of a bad state. As we are assuming quasi-concave utility, this implies that the agent's utility in a good state exceeds his utility in a bad state. This implies that the agent must be still making some loss in the case of an accident - i.e. he cannot be taking full coverage. The individual optimum under "unfair" insurance is depicted in Figure 4 at point c¢ , the tangency of the unfair insurance line G with the highest indifference curve U(c¢ ). We see we do not have full coverage as the allocation is off the 45° certainty line, so wA + b ¢ < wN - a ¢ , i.e. the loss is not fully covered. Under unfair insurance, do more risk-averse agents take more insurance than less risk-averse agents? Let u and v be two agents, where u is more risk averse than v, but both share the same subjective probabilities of an accident and the same loss. Greater risk-aversion of u is shown in Figure 5 by the greater convexity of the indifference map u relative to v. If there is fair-insurance, so p s = g and we are on the F line, then notice that both agents will have full coverage at c with u(c) and v(c).
If, however, there is unfair insurance, so we are on the G line and we know that neither agent will insure fully. As we see in Figure 5, agent u's optimal contract will be at cu and agent v's at cv (thus obtaining utilities u(cu) and u(cv) respectively). Notice that wN - a v > wN - a u, which implies that the coverage taken by agent u is greater than the coverage taken by agent v, i.e. the risk-averse take greater coverage. How can we be sure of this result? If u is more risk-averse than v, then we know by Arrow-Pratt that u = T(v) where T is a concave function. Now, at v's optimum, we know that the negative of the slope of v's indifference curve is equal to the premium ratio:
where Cv is agent v's optimal coverage. Now, let us force agent u to hold agent v's coverage. In this case, the slope of the indifference curve of agent u at allocation cv is:
or as u = T(v), so u¢ = T¢ (v)·v¢ :
or, substituting in:
thus the slope of u's indifference curve at cv is some function of the slope of v's indifference curve at cv. The crucial component is the ratio connecting them. However, it is easy to notice that as v(wN - g Cv) > v(wA + (1-g )Cv) at the allocation cv (as cv lies below the 45° line), then by the concavity of T, we know that T¢ (v(wN - g Cv)) < T¢ (v(wA + (1-g )Cv)). Consequently, the ratio [T¢ (v(wN - g Cv))/T¢ (v(wA + (1-g )Cv))] < 1. Thus the above formula implies that at allocation cv:
the marginal rate of substitution of agent u at cv is less than the marginal rate of substitution of agent v at cv, i.e. agent u's indifference curve is flatter than agent v's indifference curve. This is depicted in Figure 5 by comparing the (dashed) indifference curve u(cv) and indifference curve v(cv). Consequently, agent u's optimal insurance contract must lie further up the G curve, nearer to the 45° line, as we see at point cu. Thus, a u > a v, which implies that Cu > Cv, i.e. the more risk-averse agent takes on greater insurance coverage than the less risk-averse - as we predicted.
K.J. Arrow (1953) "The Role of Securities in the Optimal Allocation of Risk-Bearing", Econometrie; as translated and reprinted in 1964, Review of Economic Studies, Vol. 31, p.91-6. K.J. Arrow (1963) "Uncertainty and the Welfare Economics of Medical Care", American Economic Review, Vol. 53, p.941-73. K.J. Arrow (1965) Aspects of the Theory of Risk-Bearing. Helsinki: Yrjö Hahnsson Foundation. K. Borch (1968) The Economics of Uncertainty. Princeton, NJ: Princeton University Press. G. Debreu (1959) Theory of Value: An axiomatic analysis of economic equilibrium. New Haven: Yale University Press. R. Eisner and R.H. Strotz (1961) "Flight Insurance and the Theory of Choice", Journal of Political Economy, Vol. 69, p.355-68. J. Hirschleifer (1965) "Investment Decision under Uncertainty: Choice-theoretic approaches", Quarterly Journal of Economics, Vol. 79, p.509-36. J. Hirshleifer (1966) "Investment Decision under Uncertainty: Applications of the state-preference approach", Quarterly Journal of Economics, Vol. 80, p.252-77. L.J. Savage (1954) The Foundations of Statistics. 1972 edition, New York: Dover. M. Yaari (1969) "Some Measures of Risk Aversion and Their Uses", Journal of Economic Theory, Vol. 1 (2), p.315-29.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

All rights reserved, Gonçalo L. Fonseca